Plant Disease Classification with Deep Learning
Potato cultivation, crucial for global food security, is under constant threat from devastating diseases such as late blight and early blight. The reliance on manual disease identification methods exacerbates these challenges, as they are inherently time-consuming, labor-intensive, and prone to error. The statistics indicate a decline in global potato production, with figures standing at approximately 17,791,800 tonnes in 2022, down from 18,582,400 tonnes in 2021 and 19,051,800 tonnes in 2020.
The primary goal is to develop CNN models for automatic detection and classification of potato diseases from image data. Leveraging deep learning techniques, these models aim to accurately identify disease symptoms, facilitating timely interventions. Another goal is to evaluate and compare the performance of various CNN architectures, including VGG, ResNet, Inception, DenseNet, and EfficientNet. Through comprehensive assessment using metrics like accuracy, precision, recall, and AUC, the aim is to identify the most effective model for disease detection. Ultimately, the selected model will serve as a valuable tool for farmers, enabling early disease management and minimizing crop losses, thus ensuring food security.
The project begins by loading and organizing the dataset using TensorFlow's image_dataset_from_directory function, this simplifies data ingestion and expediting model development. Parameters such as random seed, image size, batch size, and shuffling were meticulously configured to ensure consistency and reproducibility. Partitioning the dataset into training, validation, and test sets was imperative for accurate model evaluation, facilitated by a custom partitioning function. Shuffling the dataset and setting a seed value maintained randomness while ensuring consistency across different runs. Despite its modest size of 2,152 images across three classes, each 256x256 pixels, the dataset proved suitable for model development, with batches configured at 32, ensuring compatibility with training processes.
Data preprocessing and augmentation are pivotal for training robust deep learning models, especially in image classification tasks. To ensure consistency in input dimensions and stabilize training, I employed resizing and rescaling techniques using TensorFlow's built-in functions. Resizing images to a uniform size and rescaling pixel values between 0 and 1 mitigated the impact of varying resolutions and enhanced model convergence during training.
For diversifying the training dataset and preventing overfitting, I implemented data augmentation techniques. Horizontal and vertical flipping introduced variations in object orientation, while random rotation simulated real-world scenarios, enhancing the model's robustness. By exposing the model to a broader range of image variations, augmentation improved its generalization capability.
Augmentation was specifically applied to the training dataset, ensuring that transformations were only applied during training to prevent data leakage. Additionally, prefetching was enabled to optimize training performance by overlapping data preprocessing and model execution.
Visual inspection of augmented images validates the effectiveness of the transformation pipeline, ensuring that semantic integrity was maintained.

Histogram analysis of pixel intensities provides insights into the diversity of augmented images, guiding parameter optimization to create a more balanced and representative training dataset.

These preprocessing and augmentation techniques enriches the training dataset with diverse image variations, enabling the CNN models to learn discriminative features effectively and improve generalization performance on unseen data.
Each chosen base model was carefully curated to leverage its unique strengths relevant to our potato plant leaf disease dataset. VGG16's simplicity and uniformity, coupled with its adeptness at fine-grained feature extraction, made it a compelling choice. ResNet50's innovative use of residual connections addressed the challenge of vanishing gradients in deeper networks, facilitating effective feature extraction. InceptionV3's multi-scale feature extraction capability, through its inception modules, suited tasks requiring nuanced feature analysis. DenseNet121's dense connectivity patterns, promoting feature reuse and gradient flow, offered a unique advantage. Lastly, EfficientNetB0's balanced scaling method ensured superior performance with minimal computational resources.
Harnessing pre-trained weights from ImageNet, we initialized these models, capitalizing on their rich understanding of visual features to expedite convergence and enhance performance. To tailor the models to our specific classification task, we adopted a strategy of freezing all layers except the last few in the selected base model. This strategic move allowed the models to retain learned features while adapting to the intricacies of our dataset.
In constructing the complete model architecture, we carefully appended additional layers, including global average pooling, dense layers with Rectified Linear Unit (ReLU) activation, and a final softmax layer for multi-class classification. Leveraging pre-trained weights imbued the models with a profound understanding of visual features, enabling them to extract meaningful representations from our dataset with minimal additional training.
By excluding the fully connected layers (top layers) of the pre-trained models using the include_top=False parameter, we afforded ourselves the flexibility to customize the models to our specific task requirements. This customization involved appending custom layers to tailor the models, ensuring they learned task-specific representations while retaining the generic features acquired during pre-training. This meticulous approach not only expedited convergence but also elevated performance, maximizing the models' capacity to generalize to unseen data.
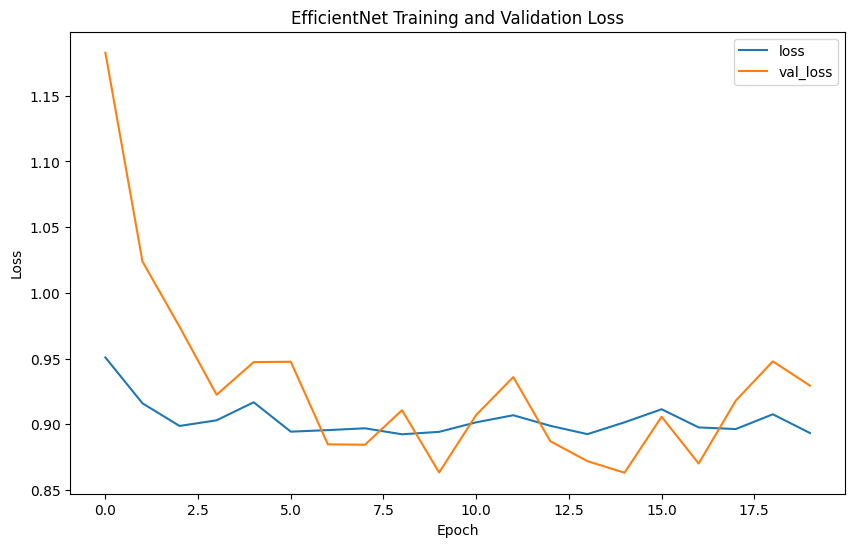
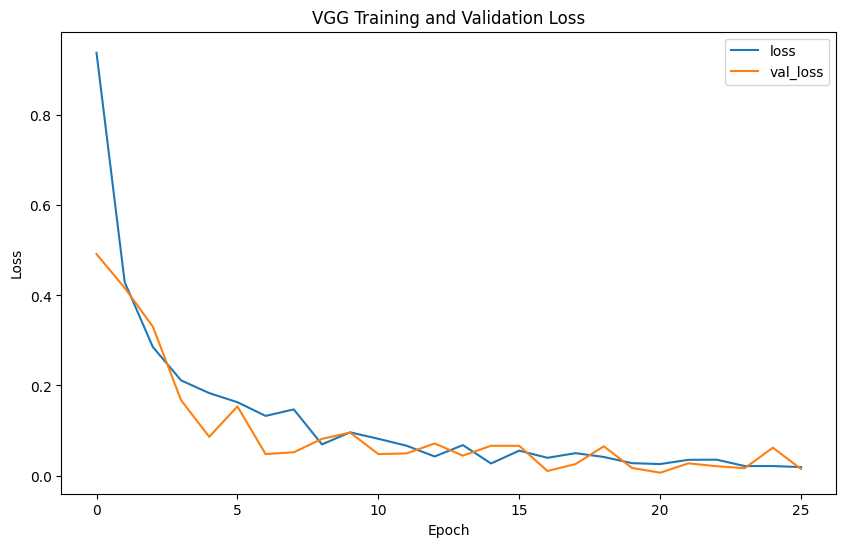
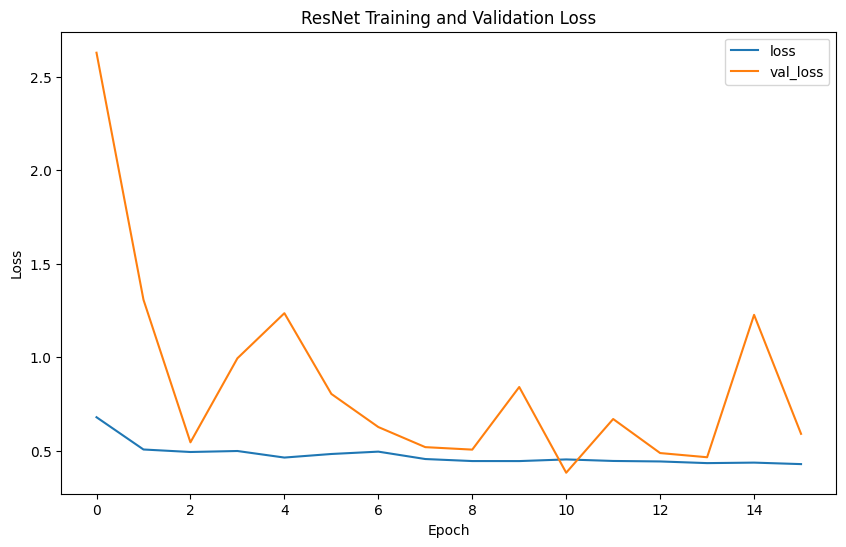
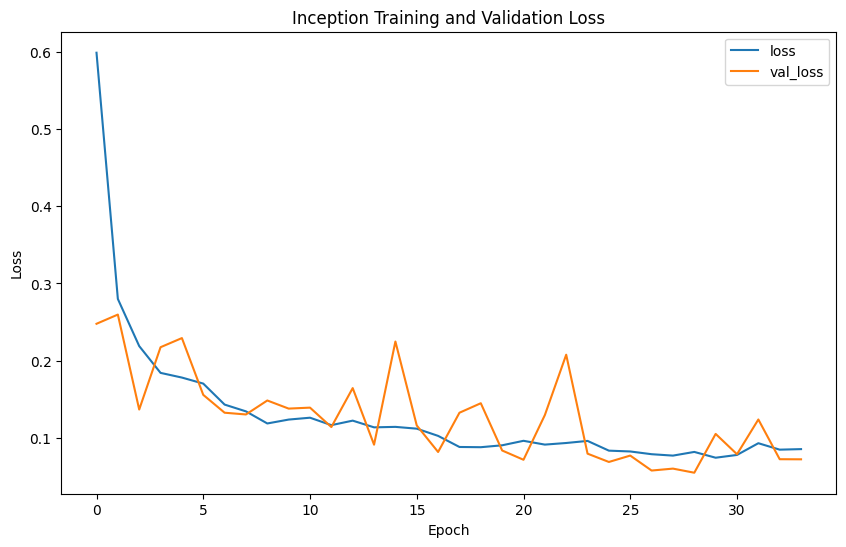
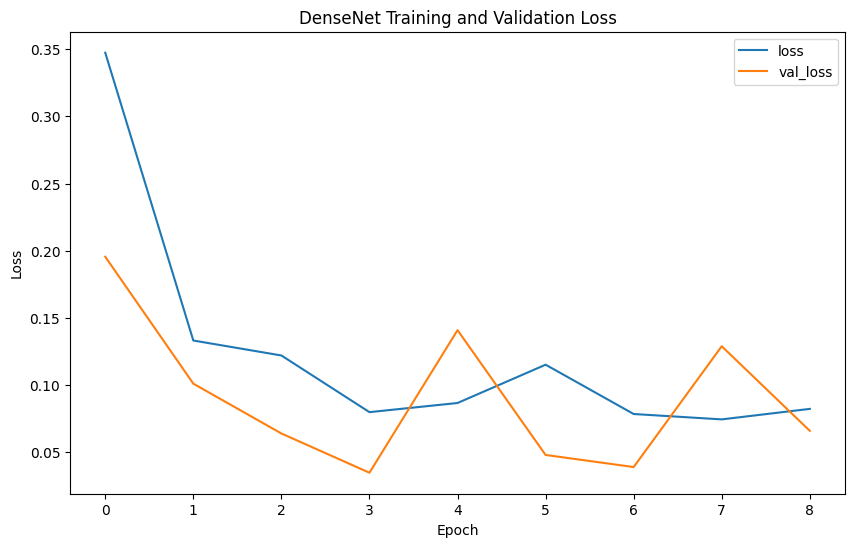
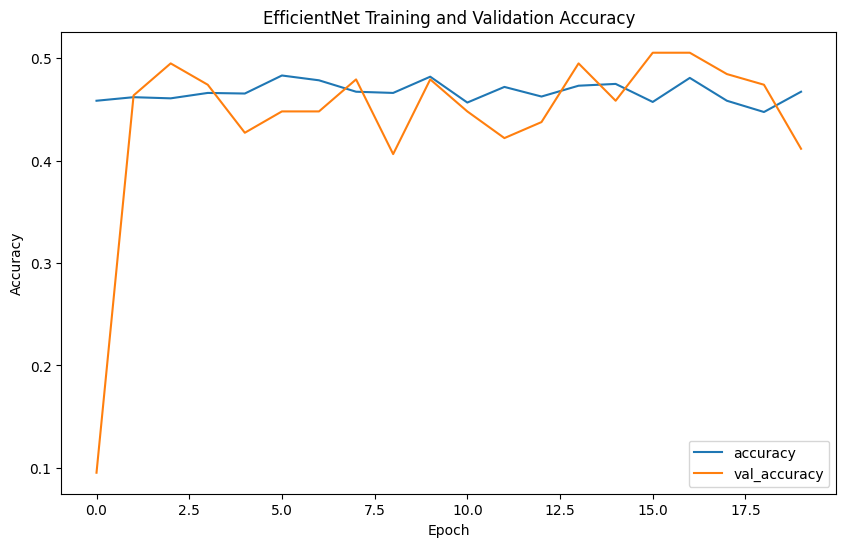
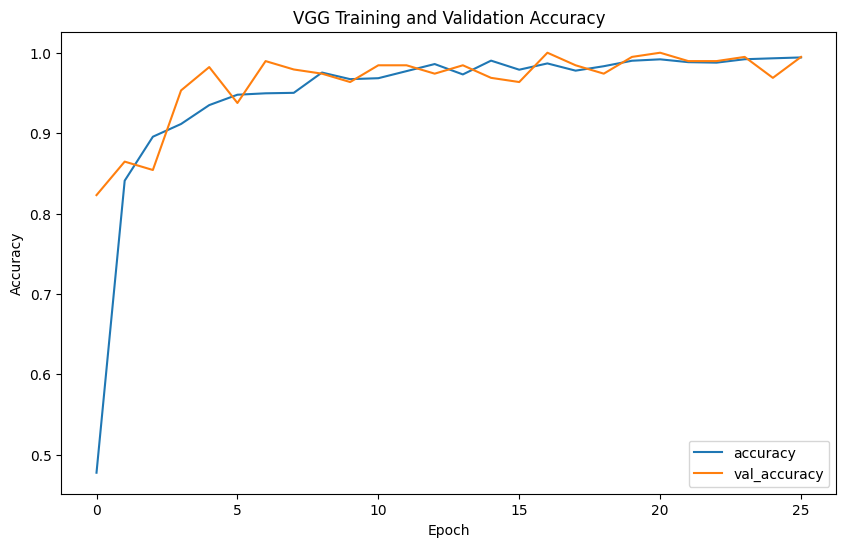
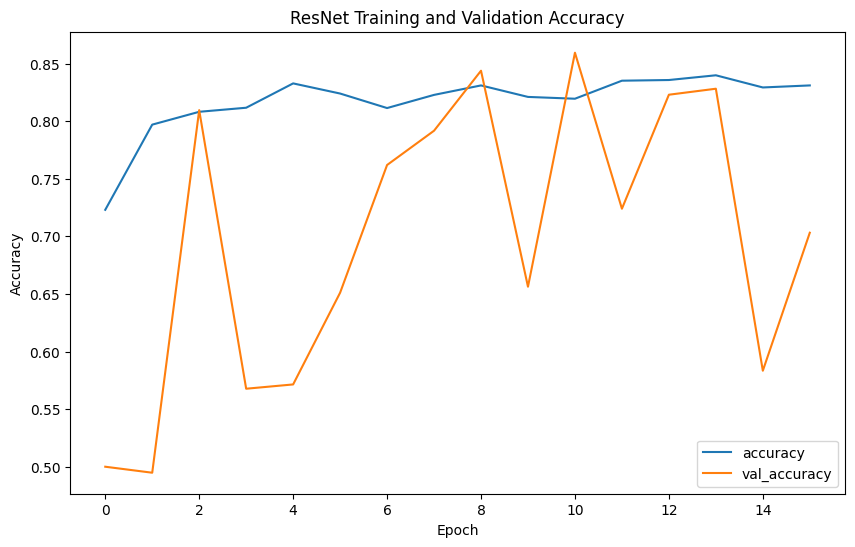
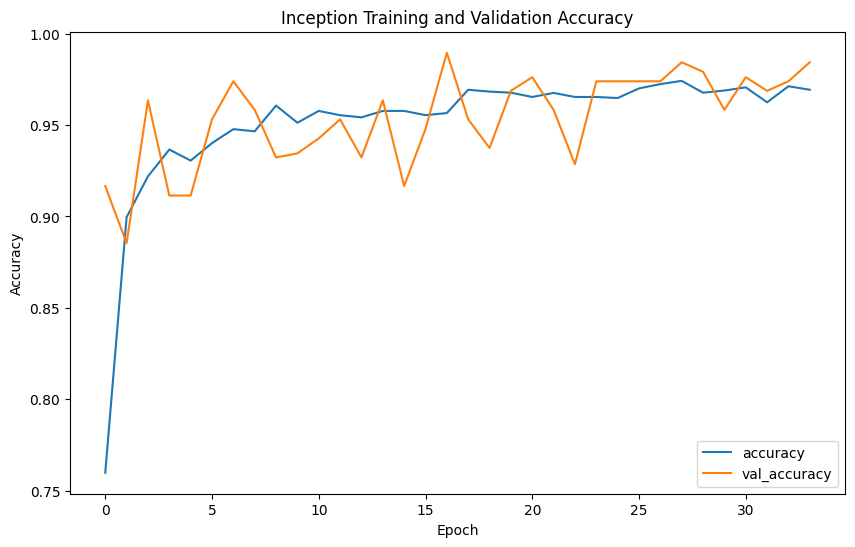
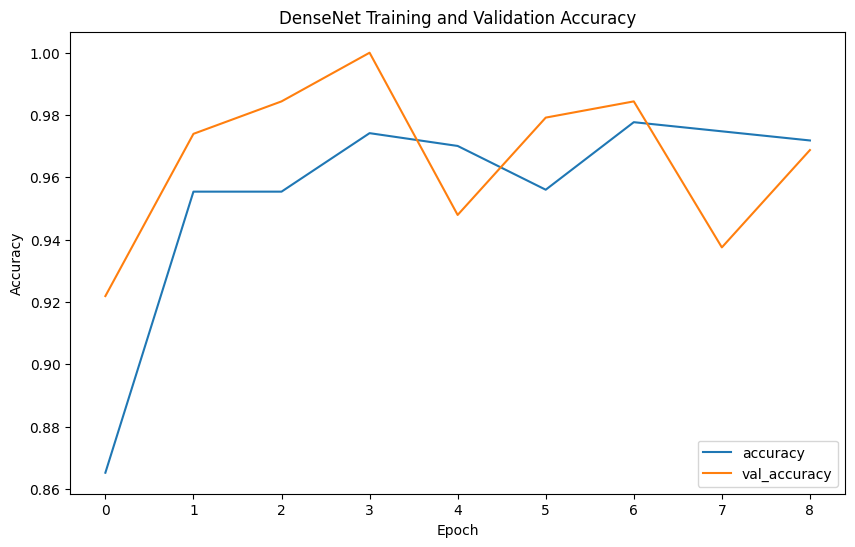
Evaluation metrics such as precision, recall, F1-score, confusion matrix, and ROC curves provide comprehensive insights into model performance. Precision measures the accuracy of the model's positive predictions, recall assesses the ability to identify all positive cases, F1-score balances precision and recall, and accuracy evaluates the overall correctness of classifications.

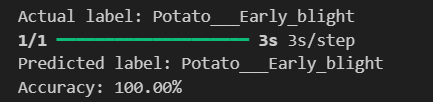
The model performance results reveal that EfficientNet has the lowest precision (0.2539) and F1-score (0.3377), indicating poor classification accuracy. In contrast, VGG shows the highest precision (0.4592), recall (0.4727), F1-score (0.4653), and accuracy (0.9957), demonstrating superior ability to correctly identify positive cases while minimizing false positives. ResNet, with balanced precision (0.4472) and recall (0.4766) and reasonable accuracy (0.8477), performs reliably. Inception mirrors ResNet's metrics but with slightly higher accuracy (0.978), indicating strong overall performance. DenseNet also performs comparably to ResNet and Inception, with balanced precision (0.4489), recall (0.4746), F1-score (0.4602), and accuracy (0.9492). Overall, VGG emerges as the most robust model, achieving the highest accuracy and consistent performance across metrics.